DesignMuseum
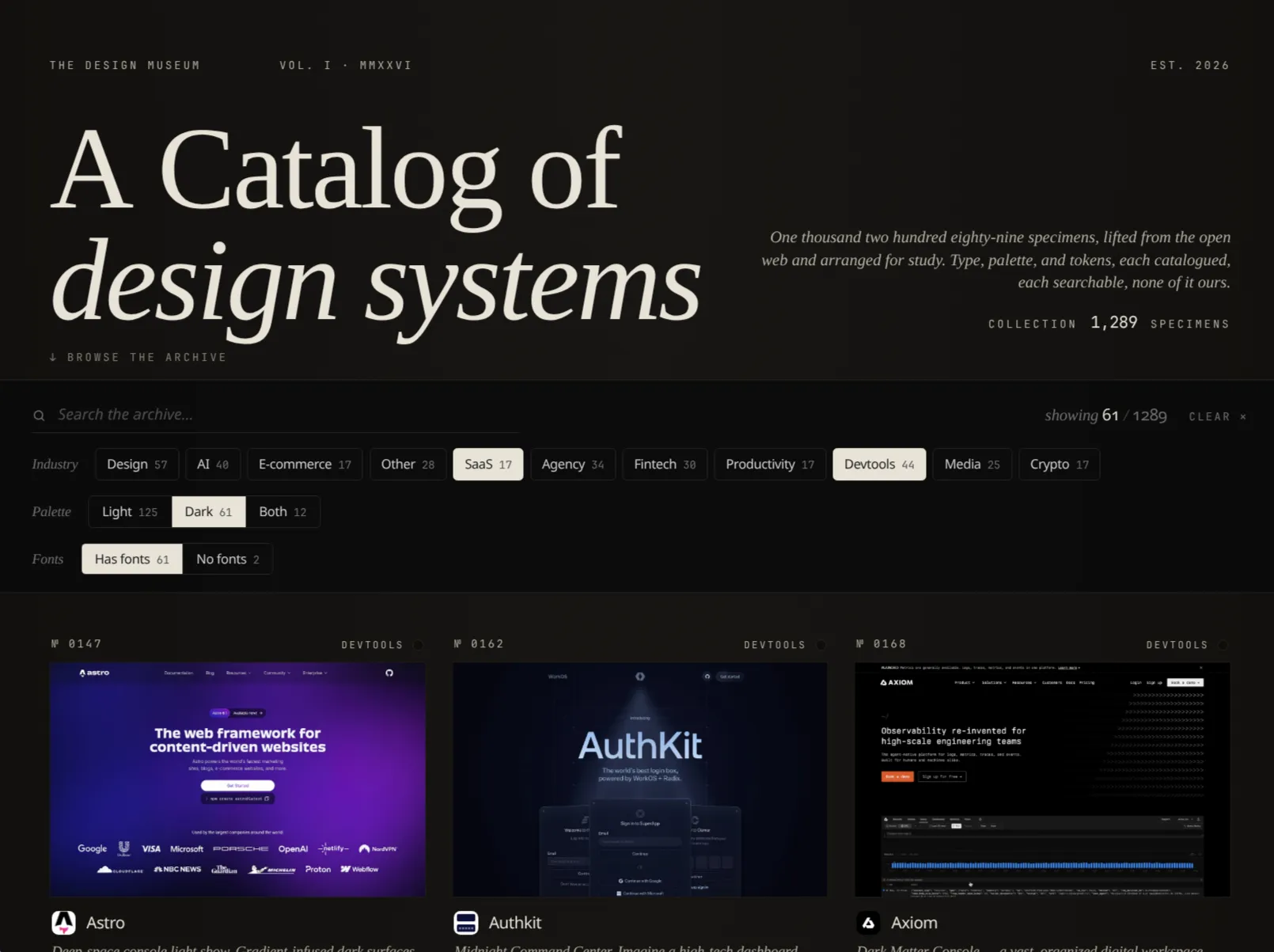
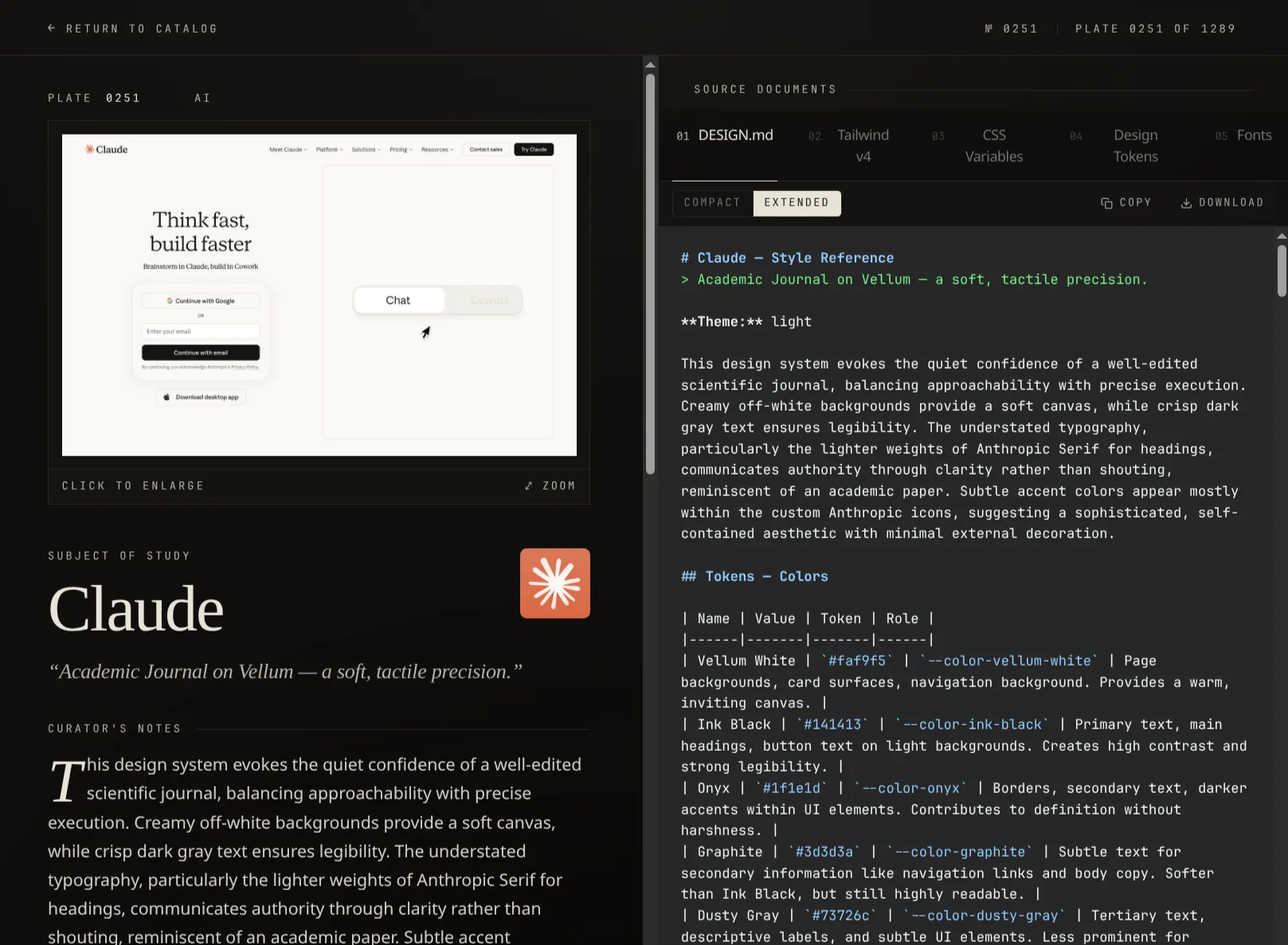
DesignMuseum is a private, git-tracked archive of 1,289 design systems: color palettes, typography scales, Tailwind v4 tokens, CSS variables, design tokens, and the actual web fonts (WOFF2) each site ships. Every entry lives in its own directory of plain-text files plus a fonts/ subdirectory, indexed by a deterministic slug, so an LLM can grep for border-radius: 28px across every site at once or pull a real .woff2 straight off disk without round-tripping to the live web. That’s the load-bearing use case: ground truth for agentic coding, where the agent needs the real spec for a real site rather than its training-time approximation of one.
The stack has four moving parts and nothing else: a Node CLI that walks an upstream sitemap (crawler/), the vault itself (vault/), a SQLite database that tracks crawl state and only crawl state (crawler/state.db), and an Astro 5 SSG that renders the vault into a static site (astro/). No server, no daemon, no scheduler. Crawling is a manual batch job and the site is a one-shot static build.
1. The capture pipeline is fully deterministic
The crawler runs no LLMs at any point. Given a fixed upstream state, the same GUID produces byte-for-byte identical output across runs. I verified this empirically across three live runs of varying staleness; every captured file’s size and SHA stayed stable.
The pipeline is structured around one observation: the upstream is a Next.js client-render shell that calls /api/styles/<guid> shortly after hydration, then templates the response into a tabbed file viewer. v1 tried to skip the browser entirely and synthesize the eight output files from the API JSON. It didn’t survive contact with reality, because the upstream renderer pulls from a dozen interlocking fields (custom narrative sections, gradient strings embedded inside colors, a 56-entry spacing scale) that drift whenever they tune their templates. v2 captures the rendered DOM instead.
Each per-page crawl looks like this:
const browser = await chromium.launch();
const ctx = await browser.newContext({ userAgent: "DesignMuseum-Crawler/0.1" });
const page = await ctx.newPage();
const responsePromise = page.waitForResponse(r => r.url().includes(`/api/styles/${guid}`));
await page.goto(stylePageUrl, { waitUntil: "domcontentloaded" });
const raw = await (await responsePromise).json();
validateStyleResponse(raw, guid);The JSON interceptor is set up before navigating, so it races against the page load and resolves whenever the API call happens to fire. Then the tab walk: click each file tab, click the Compact/Extended toggle, read textContent from the visible <pre> inside the active <role=tabpanel>. Eight combinations per page (four file types × two variants). The DOM has two role="tab" lists with the same accessible names, so I use .first() to enter the file viewer and .last() to drive the secondary tablist that owns the Compact/Extended toggle.
Writes to disk are atomic. Either a slug directory is complete or it doesn’t exist:
const tmp = path.join(vaultRoot, `.tmp-${slug}-${process.pid}-${Date.now()}`);
await fs.mkdir(tmp, { recursive: true });
await writeAllFiles(tmp, captured);
await fs.rm(finalDir, { recursive: true, force: true });
await fs.rename(tmp, finalDir);The slug rule is its own small problem. Sites have names like Apple, Apple (España), mymind, 8returns, and one entry whose name is purely Korean script (큰그림컴퍼니). The rule:
function slugFor(siteName: string, guid: string): string {
const k = kebab(siteName);
return `${k || "site"}-${guid.slice(0, 8)}`;
}kebab normalizes via NFKD, strips Unicode combining marks, lowercases, collapses non-alphanumeric runs to dashes. The || "site" fallback catches anything that kebabs to empty; without it, the Korean entry would slug to -eafe33bf, which crashes filesystem semantics on more than one OS. The 8-character GUID suffix disambiguates the multiple “Apple” entries while keeping the directory name human-readable.
SQLite never stores design content. The schema is (guid, site_name, slug, source_url, crawled_at) plus a side-table for failures, full stop. Design content lives as files in git, so git diff vault/apple-c9cabb96/DESIGN.extended.md is the diff I actually want to read when an upstream system gets refreshed. A SQLite-blob diff would be unreadable. Tombstones are a site_name = '__deleted__' row: upstream 404s get tombstoned automatically so retries never re-fetch them, and the Korean-script entry above is tombstoned by hand to keep it out of the vault.
2. The font crawl bypasses the upstream entirely
The fonts are the most interesting layer. They aren’t captured from the upstream catalog at all; they’re pulled directly from each site’s live origin.
crawl-fonts opens the original source_url in a fresh Playwright context, lets the page settle, and enumerates the loaded font set from inside the page:
const fonts = await page.evaluate(() =>
Array.from(document.fonts).map(f => ({
family: f.family,
weight: Number(f.weight) || 400,
style: f.style,
})),
);The document.fonts API returns every FontFace the browser actually resolved after CSS settled, which is the only honest answer to “what fonts does this site use?” Static CSS analysis misses anything loaded conditionally.
The non-obvious bit is the binary fetch. Many sites front their assets with Vercel or Cloudflare CDNs that 429 a same-IP same-UA Node fetch, but happily serve the same URL when the request originates from the live page itself. So the font bytes get pulled inside the same browser context, not via Node:
const bytes = await page.evaluate(async (url) => {
const r = await fetch(url);
return Array.from(new Uint8Array(await r.arrayBuffer()));
}, sourceUrl);Piggybacking on the page’s own request credentials and Origin header sidesteps the rate limiter; the request is the page asking for its own assets. A 50-face cap per site keeps the long tail of foundry showcase pages (some declare hundreds of variants) from drowning the vault.
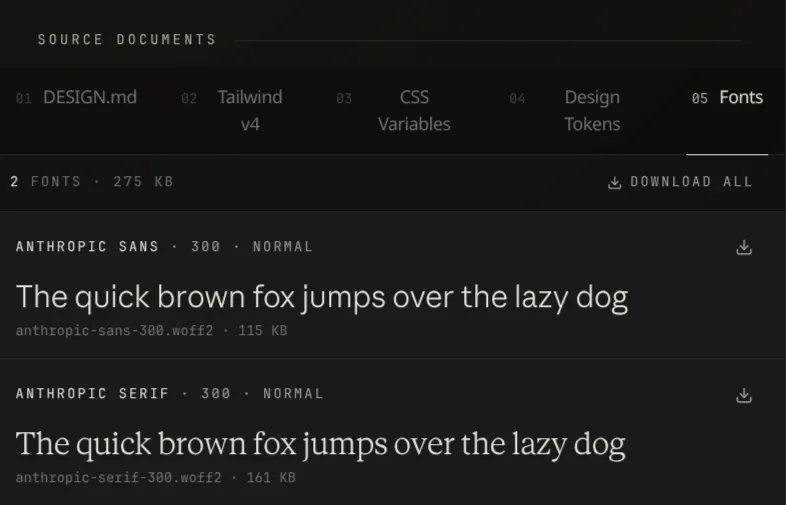
Output is vault/<slug>/fonts/ plus a _index.json manifest of {family, weight, style, format, file, source_url} records, used downstream to render live @font-face previews in the site.
3. The Astro site is a pure SSG
The browsing layer is Astro 5 in fully static mode. No SSR, no client framework, no hydration. The vault is exposed at /vault/ via a single relative symlink (astro/public/vault → ../../vault); the build resolves it into dist/ as one self-contained directory.
A full build of 1,289 detail pages plus the home, plus 404, plus the resolved vault, takes around 40 seconds on a modern laptop. Shiki dominates: roughly 10,000 syntax-highlight calls across the eight (file × variant) blocks per page. The rest is fs.readFile per slug.
The only client work is the home-page filter bar. Three rows of facets (industry, color scheme, fonts), a debounced search input, and the entire runtime is ~170 LOC of vanilla TypeScript bundled by Vite. The trick that makes it cheap: the per-entry filter records are emitted into the page as one JSON blob, then the runtime walks that array in memory on every state change.
<script type="application/json" id="entries-data">
[{ "slug": "apple-c9cabb96", "siteName": "Apple", "industry": "ecommerce",
"colorScheme": "light", "hasFonts": true, "searchText": "apple ..." }]
</script>Filter semantics are OR within a facet, AND across facets. On each change, the runtime toggles a .hidden class on the matching <li>s, recomputes faceted counts (industry counts respect the active color and fonts filters, and so on), and rewrites the URL via history.replaceState. Clear uses pushState so the back button restores the filtered view, and a popstate listener keeps state in sync with browser navigation. An inline <script is:inline> preamble applies the URL-derived filter synchronously before the deferred main script loads, so reloading ?industry=ai&fonts=yes never flashes an unfiltered grid.
The pure filter logic lives in src/lib/home-filter.ts with no DOM and no globals, and ships with 36 Vitest cases covering match, query round-trips, faceted counts, and the fonts axis. Keeping the logic and the DOM glue in separate files is the same reason the crawler’s slug rule is a pure function: easy to test now, easy to retarget later.
The Fonts tab on each detail page reuses the same idea one layer up. The Astro component reads _index.json, emits an inline <style> block with one @font-face rule per file (each face uniquely named font-<slug>-<index> to avoid colliding with the page’s own typography), and renders a row per face with a font-family: font-<slug>-<index> applied to a sample string. The previews are the real woff2 files loaded straight off disk, not screenshots; a single “Download all” button zips the whole set client-side and saves <slug>-fonts.zip. JSZip in the browser, no server step.
4. What the stack deliberately doesn’t have
The whole thing is TypeScript everywhere, strict mode with noUncheckedIndexedAccess and exactOptionalPropertyTypes, ESM with .js import extensions, plus the smallest possible dependency surface I could justify. No logger library (Node’s console is fine for a CLI), no CLI parser dep (Node’s built-in parseArgs covers seven flags), no client framework on the Astro side (~210 LOC of vanilla JS covers every interaction the site has), and no mocks in tests — Vitest reads the real fixture vault from disk and the live integration test hits the real API. The only place I was tempted into something heavier was the font crawl, and even there the answer turned out to be “use the browser you already have.”